- — Mavzular ma'lumotlarini himoya qilish EN so'zdan foydalanish chastotasi ... Texnik tarjimon uchun qo'llanma
Y; chastotalar; va. 1. Tez-tez (1 ta raqam). Harakatlarni takrorlash chastotasini kuzatib boring. Kartoshkani ekishning zarur qismi. Puls tezligiga e'tibor bering. 2. Bir xil harakatlarning takrorlanish soni, qaysi yo'nalishdagi tebranishlar. vaqt birligi. G'ildirakning aylanish soatlari. H... ensiklopedik lug'at
I Alkogolizm - bu spirtli ichimliklarni muntazam ravishda suiiste'mol qilish natijasida kelib chiqadigan ruhiy va somatik kasalliklarning kombinatsiyasi bilan tavsiflangan surunkali kasallik. A. x ning eng muhim ko'rinishlari. chidamlilik ...... ga o'zgaradi. Tibbiy ensiklopediya
QO'lga olish- ruscha kanca yozuvlarida ishlatiladigan o'ziga xos atamalardan biri. chiziqli bo'lmagan polifoniya, rivojlangan subvokal polifonik tuzilish va vertikalning keskin dissonansi bilan tavsiflanadi. Qo'shiq aytish hozirgi kunda muddatni amalga oshirish. vaqt o'rganilmagan ... Pravoslav entsiklopediyasi
Matnni tahlil qilishning stilostatistik usuli- nutqda tilning faoliyat turlarini, tilning turli muloqot sohalarida faoliyat ko'rsatish qonuniyatlarini, matn turlarini, o'ziga xos funksiyalarini aniqlash uchun stilistika sohasidagi matematik statistika vositalaridan foydalanishdir. uslublar va ...
Porsiyalangan xushbo'y snus, mini portsiyali Snus tamaki mahsulotining bir turi. U ezilgan namlangan tamaki bo'lib, u yuqori (kamroq pastki) lab va saqich o'rtasida joylashgan ... Vikipediya
Ilmiy uslub- ilmiy taqdim etadi. ijtimoiy ong shakli sifatida fanni amalga oshirish bilan bog'liq muloqot va nutq faoliyati sohasi; nazariy tafakkurni aks ettiradi, kontseptual mantiqiy shaklda namoyon bo'ladi, bu ob'ektivlik va mavhumlik bilan ajralib turadi... Rus tilining stilistik ensiklopedik lug'ati
- (ixtisoslashtirilgan adabiyotlarda otasining ismi ham) familiyaning bolaga otasining ismi bilan beriladigan qismi. Ota ismining o'zgarishi ularning egalarini uzoqroq ajdodlar, bobolar, bobolar bilan bog'lashi mumkin... ... Vikipediya
Umumiy foydalanish, qo'llanilishi, tarqalishi, qo'llanilishi, sotilishi, umumiy qabul qilingan Rus sinonimlarining lug'ati. foydalanish nomi, sinonimlar soni: 10 umumiy qabul qilingan (11) ... Sinonim lug'at
Mulohaza yuritish- - nutqning funktsional semantik turi (qarang) - (FSTR), mavhum fikrlash shakliga mos keladigan - xulosa chiqarish, maxsus kommunikativ vazifani bajarish - nutqqa asosli xarakter berish (mantiqiy ravishda yangi hukm chiqarish yoki ... ... Rus tilining stilistik ensiklopedik lug'ati
Men kulgili PHP skriptini yozdim. Tilni tekshirish uchun “Tomoshabin”dagi barcha matnlarni u orqali o‘tkazdim. Matnlarda jami 39110 xil so‘z shakllari qo‘llangan. Aynan nechtasi turlicha? so'zlar- aniqlash juda qiyin. Hech bo'lmaganda bu raqamga yaqinroq bo'lish uchun men so'zning faqat birinchi 5 ta harfini oldim va ularni taqqosladim. Natijada 14 373 ta shunday kombinatsiya paydo bo'ldi. Buni "Tomoshabin" lug'ati deb atash qiyin bo'lardi.
Keyin men so'zlarni oldim va ularni harflarning takrorlanish chastotasi uchun tekshirdim. Ideal holda, rasmni to'ldirish uchun qandaydir lug'atni olishingiz kerak. Siz matnlarni ishlata olmaysiz, faqat noyob so'zlar kerak. Matnda ba'zi so'zlar boshqalarga qaraganda tez-tez takrorlanadi. Shunday qilib, quyidagi natijalarga erishildi:
o - 9,28%
a - 8,66%
e - 8,10%
va - 7,45%
n - 6,35%
t - 6,30%
p - 5,53%
s - 5,45%
l - 4,32%
ichida - 4,19%
k - 3,47%
n - 3,35%
m - 3,29%
y - 2,90%
d - 2,56%
I - 2,22%
s - 2,11%
b - 1,90%
z - 1,81%
b - 1,51%
g - 1,41%
th - 1,31%
h - 1,27%
yu - 1,03%
x - 0,92%
f - 0,78%
w - 0,77%
c - 0,52%
sch - 0,49%
f - 0,40%
e - 0,17%
' - 0,04%
Men "Mo''jizalar maydoni" ga boradiganlarga ushbu jadvalni yodlashni maslahat beraman. Va so'zlarni shu tartibda nomlang. Shunday qilib, masalan, bunday "tanish" "b" harfi "nodir" "s" harfiga qaraganda kamroq qo'llaniladi. So'zda bir nechta unli borligini ham unutmasligimiz kerak. Va agar siz bitta unlini taxmin qilgan bo'lsangiz, unda undoshlarga ergashishni boshlashingiz kerak. Bundan tashqari, so'z undoshlari bilan aniq taxmin qilinadi. Taqqoslang: “**a**i*e” va “sr*vn*t*”. Ikkala holatda ham so'z "taqqoslash" dir.
Va yana bir fikr. Ingliz tilini qanday o'rgandingiz? Esingizdami? E qalam, elektron qalam, elektron stol. Men ko'rgan narsam haqida qo'shiq aytaman. Buning nima keragi bor?.. Oddiy hayotda “qalam” so‘zini qanchalik tez-tez aytasiz? Agar vazifa iloji boricha tez va samarali gapirishni o'rgatish bo'lsa, unda siz shunga mos ravishda o'rgatishingiz kerak. Biz tilni tahlil qilamiz va eng ko'p ishlatiladigan so'zlarni ta'kidlaymiz. Va biz ulardan o'rganishni boshlaymiz. Ingliz tilida ko'proq yoki kamroq gapirish uchun bir yarim ming so'z kifoya qiladi.
Yana bir erkalash: oddiy so'zlarga o'xshab ko'rinishi uchun harflardan tasodifiy, lekin paydo bo'lish chastotasini hisobga olgan holda so'zlarni shakllantirish. Birinchi o'nta "tasodifiy" to'rt harfli so'zda "eshak" paydo bo'ldi. Keyingi ellikta - "shoshilish" va "NATO" so'zlari. Ammo, afsuski, "bltt" yoki "nrro" kabi juda ko'p dissonant kombinatsiyalar mavjud.
Shuning uchun - keyingi qadam. Men barcha so'zlarni ikki harfli birikmalarga ajratdim va ularni tasodifiy birlashtira boshladim (lekin takrorlanish chastotasini hisobga olgan holda). Ko'p miqdorda po'lat "oddiy" ga o'xshash so'zlarni hosil qiladi. Masalan: "koivdiot", "voabma", "apy", "depoid", "debyako", "orfa", "poesnavy", "ozza", "chenya", "ritoria", "urdeed", "utoichi" , "stikh", "sapot", "gravda", "ababap", "obarto", "eleuet", "lyarezy", "myni", "bromomer" va hatto "todebyst".
Qaerga murojaat qilish kerak ... variantlar mavjud. Masalan, chiroyli markali o'ynoqi ismlarning generatorini yozing. Yogurtlar uchun. Masalan, "memoliso" yoki "utororerto". Yoki - "Burliuk-php" futuristik she'rlar generatori: "opeldiy miaton, linoaz okmiaya... deesopen odesson".
Va yana bitta variant bor. Sinab ko'rish kerak...
Ruscha so'zlardan foydalanish bo'yicha ba'zi statistik ma'lumotlar:
- O'rtacha so'z uzunligi 5,28 belgi.
- O'rtacha jumla uzunligi 10,38 so'z.
- 1000 ta eng tez-tez uchraydigan lemmalar matnning 64,0708% ni qamrab oladi.
- 2000 yilda eng ko'p uchraydigan lemmalar matnning 71,9521% ni qamrab oladi.
- 3000 ta eng tez-tez uchraydigan lemmalar matnning 76,5104% ni qamrab oladi.
- 5000 ta eng tez-tez uchraydigan lemmalar matnning 82,0604% ni qamrab oladi.
Eslatmadan keyin men ushbu xatni oldim:
Salom Dmitriy!"Til sizni Kievga olib keladi" maqolasini va dasturingizni tasvirlaydigan qismni tahlil qilgandan so'ng, bir fikr paydo bo'ldi.
Siz yozgan stsenariy ko'proq "Mo''jizalar maydoni" uchun emas, balki boshqa narsa uchun mo'ljallangandek tuyuladi.
Skriptingiz natijalaridan birinchi eng oqilona foydalanish mobil qurilmalar uchun tugmalarni dasturlashda harflar tartibini aniqlashdir. Ha, ha - bularning barchasi mobil telefonlarda kerak.Men uni to'lqinlarga tarqatdim ()
Tugmalar bo'yicha tarqatish quyidagicha:
1. Birinchi to'lqinning barcha harflari birinchi qatordagi 4 ta tugmaga o'tadi
2. Ikkinchi to'lqinning barcha harflari ham xuddi shu birinchi qatordagi qolgan 4 ta tugmada
3. Uchinchi to'lqinning barcha harflari qolgan ikkita tugmachaga o'tadi
4. 4,5 va 6 to'lqinlar ikkinchi qatorga o'tadi
5. 7,8,9 to‘lqinlar uchinchi qatorga o‘tadi, 9-to‘lqin esa to‘liq (ko‘p ko‘rinadigan harflar soniga qaramay) 9-tugmaning uchinchi qatoriga o‘tadi, shuning uchun 10-tugma barcha turdagi tinish belgilari uchun qoldiriladi. belgilar (nuqta, vergul va boshqalar).Menimcha, hamma narsa aniq, batafsil tushuntirishlarsiz. Ammo shunga qaramay, skriptingiz bilan (shu jumladan tinish belgilarini) quyidagi matnlarni qayta ishlay olasizmi:
Va keyin statistikani joylashtirasizmi? Menga ko'rindiki? matnlar iloji boricha zamonaviy nutqimizni aks ettiradi va shunga qaramay biz ham gaplashamiz, ham SMS yozamiz.
Oldindan katta rahmat.
Shunday qilib, harflarning takrorlanish chastotasini tahlil qilishning ikki yo'li mavjud. 1-usul.Matn oling, undagi o‘ziga xos (takrorlanmaydigan) so‘z shakllarini toping va ularni tahlil qiling. Usul statistik ma'lumotlarni matnlarga emas, balki rus tilidagi so'zlarga asoslangan holda tuzish uchun yaxshi. 2-usul. Matnda noyob so'zlarni qidirmang, lekin to'g'ridan-to'g'ri harflarning takrorlanish chastotasini hisoblashga o'ting. Biz harflar chastotasini ruscha so'zlarda emas, balki ruscha matnda olamiz. Klaviatura va boshqa narsalarni yaratish uchun aynan shu usuldan foydalanish kerak: matnlar klaviaturada yoziladi.
Klaviaturalar nafaqat harflarning chastotasini, balki eng doimiy so'zlarni (so'z shakllari) ham hisobga olishi kerak. Qaysi so'zlar eng ko'p ishlatilishini taxmin qilish unchalik qiyin emas: bular, birinchi navbatda, rasmiy gap qismlari, chunki ularning roli har doim va hamma joyda xizmat qiladi va roli muhim bo'lmagan olmoshlar: nutqda biron bir narsani / shaxsni almashtirish (bu, u, u). Xo'sh, asosiy fe'llar (bo'lish, aytish). Yuqorida sanab o'tilgan matnlarni tahlil qilish natijalariga ko'ra, men quyidagi "mashhur" so'zlarni oldim: "va, emas, in, bu, u, men, on, bilan, u, qanday, lekin, uning, bu, to , a, hamma, uning, edi, shunday, keyin, dedi, chunki, sen, oh, at, uni, men, faqat, uchun, men, ha, sen, dan, edi, qachon, dan, uchun, hali, hozir , ular, dedilar, allaqachon, uni, yo'q, edi, uni, to be, yaxshi, na, agar, juda, hech narsa, bu yerda, o'zi, shunday qilib, o'ziga, bu, balki, o'sha, oldin, biz, ular, bormi, bormi, is, qaraganda, yoki, uning” va hokazo.
Klaviaturaga qaytadigan bo'lsak, klaviaturada "yo'q", "nima", "u", "on" va boshqalar harf birikmalari iloji boricha bir-biriga yaqin bo'lishi kerak yoki agar yaqin bo'lmasa, u holda optimal darajada bo'lishi kerak. yo'l. Barmoqlarning klaviatura bo'ylab qanday harakatlanishi, eng "qulay" pozitsiyalarni topish va ulardagi eng ko'p ishlatiladigan harflarni joylashtirish bo'yicha tadqiqot o'tkazish kerak, ammo harf birikmalari haqida unutmang.
Muammo, har doimgidek, bitta: Noyob klaviatura yaratish mumkin bo'lsa ham, qwerty/ytsukenga allaqachon o'rganib qolgan millionlab odamlar bilan nima bo'ladi?
Mobil qurilmalarga kelsak ... Ehtimol, bu mantiqiydir. Hech bo'lmaganda, "o", "a", "e" va "i" harflari aynan bir xil kalitda bo'lishi kerak. Tinish belgilari qo'llanish chastotasi bo'yicha: , . - ? ! " ; :) (
Men sizni ogohlantirmoqchimanki, ushbu maqolada keltirilgan ma'lumotlar biroz eskirgan. Keyinchalik SEO standartlari vaqt o'tishi bilan qanday o'zgarishini solishtirish uchun men uni qayta yozmadim. Ushbu mavzu bo'yicha eng so'nggi ma'lumotlarni yangi materiallarda topishingiz mumkin:
Salom, aziz blog o'quvchilari. Bugungi maqola yana veb-saytlarni qidiruv tizimini optimallashtirish () kabi mavzuga bag'ishlanadi. Ilgari biz bunday kontseptsiya bilan bog'liq ko'plab masalalarga to'xtalib o'tdik.
Bugun men ichki SEO haqida suhbatni davom ettirmoqchiman, shu bilan birga ilgari ko'tarilgan ba'zi fikrlarga aniqlik kiritib, shuningdek, biz hali muhokama qilmagan narsalar haqida gaplashmoqchiman. Agar siz yaxshi noyob matnlarni yozishga qodir bo'lsangiz, lekin ular qidiruv tizimlari tomonidan qanday qabul qilinishiga etarlicha e'tibor bermasangiz, ular sizning ajoyib mavzuingiz bilan bog'liq so'rovlar uchun qidiruv natijalarining yuqori qismiga chiqa olmaydi. maqolalar.
Qidiruv so'roviga matnning mos kelishiga nima ta'sir qiladi?
Va bu juda achinarli, chunki bu bilan siz o'zingizning loyihangizning to'liq imkoniyatlarini tushunolmaysiz, bu juda ta'sirli bo'lib chiqishi mumkin. Siz tushunishingiz kerakki, qidiruv tizimlari ko'pincha o'z imkoniyatlaridan tashqariga chiqa olmaydigan va loyihangizga inson ko'zlari bilan qarashga qodir bo'lmagan ahmoq va sodda dasturlardir.
Ular sizning loyihangizda yaxshi va zarur bo'lgan hamma narsani ko'rmaydilar (siz tashrif buyuruvchilar uchun tayyorlagan). Ular faqat matnni ko'plab komponentlarni hisobga olgan holda tahlil qilishni bilishadi, lekin ular hali ham inson idrokidan juda uzoqda.
Shuning uchun, biz hech bo'lmaganda vaqtincha qidiruv robotlarining poyafzaliga kirishimiz va turli xil qidiruv so'rovlari uchun turli matnlarni tartiblashda ular nimaga e'tibor qaratishlarini tushunishimiz kerak (). Va buning uchun siz haqida tasavvurga ega bo'lishingiz kerak, buning uchun siz taqdim etilgan maqolani o'qib chiqishingiz kerak bo'ladi.
Odatda ular sahifa sarlavhasida, ba'zi ichki sarlavhalarda kalit so'zlardan foydalanishga harakat qilishadi, shuningdek ularni maqola davomida bir tekis va iloji boricha tabiiy ravishda tarqatadilar. Ha, albatta, matndagi ta'kidlash tugmalaridan ham foydalanish mumkin, ammo ortiqcha optimallashtirish haqida unutmaslik kerak, buning natijasida yuzaga kelishi mumkin.
Matndagi kalitlarning zichligi ham muhim, ammo endi bu kerakli omil emas, aksincha, ogohlantirish - uni haddan tashqari oshirmaslik kerak.
Hujjatda kalit so'zning paydo bo'lish zichligini aniqlash juda oddiy. Darhaqiqat, bu hujjatda uning paydo bo'lish sonini hujjatning so'zlardagi uzunligiga bo'lish orqali aniqlanadigan matnda foydalanish chastotasi. Ilgari saytning qidiruv natijalaridagi o'rni bevosita bunga bog'liq edi.
Ammo siz barcha materiallarni faqat kalitlardan yig'ib bo'lmasligini tushunasiz, chunki u o'qib bo'lmaydi va Xudoga shukur, bu kerak emas. Nega, deb so'rayapsizmi? Ha, chunki matnda kalit so'zdan foydalanish chastotasining chegarasi mavjud, shundan so'ng ushbu kalit so'zni o'z ichiga olgan so'rov uchun hujjatning dolzarbligi endi oshmaydi.
Bular. Biz uchun ma'lum bir chastotaga erishish etarli bo'ladi va biz uni iloji boricha optimallashtiramiz. Yoki biz haddan tashqari oshirib, filtr ostiga tushamiz.
Ikkita savolni (va ehtimol uchta) hal qilish kerak: kalit so'zning paydo bo'lishining maksimal zichligi nima, undan keyin uni ko'paytirish xavfli, shuningdek, aniqlash.
Gap shundaki, urg'u teglari bilan ta'kidlangan va TITLE yorlig'iga kiritilgan kalit so'zlar matnda paydo bo'ladigan o'xshash kalit so'zlarga qaraganda ko'proq qidiruv vazniga ega. Ammo yaqinda veb-ustalar bundan foydalanishni boshladilar va bu omilni butunlay spam qildilar, shuning uchun uning ahamiyati pasayib ketdi va hatto kuchli nuqtalarni suiiste'mol qilish tufayli butun saytni taqiqlashga olib kelishi mumkin.
Ammo TITLE-dagi kalitlar hali ham dolzarbdir, ularni u erda takrorlamaslik va bitta sahifa sarlavhasiga juda ko'p joylashtirmaslik yaxshiroqdir. Agar kalit so'zlar TITLEda bo'lsa, biz maqoladagi ularning sonini sezilarli darajada kamaytirishimiz mumkin (va shuning uchun uni o'qishni oson va qidiruv tizimlari uchun emas, balki odamlar uchun mosroq qilish), bir xil ahamiyatga ega, ammo tushib qolish xavfisiz. filtr.
O'ylaymanki, bu savolda hamma narsa aniq - urg'u va TITLE teglariga qancha kalitlar qo'yilgan bo'lsa, birdaniga hamma narsani yo'qotish ehtimoli shunchalik yuqori bo'ladi. Ammo agar siz ulardan umuman foydalanmasangiz, unda siz ham hech narsaga erisha olmaysiz. Eng muhim mezon - matnga kalit so'zlarni kiritishning tabiiyligi. Agar ular mavjud bo'lsa, lekin o'quvchi ularga qoqilmasa, unda hamma narsa ajoyib.
Endi hujjatda kalit so'zdan foydalanishning qaysi chastotasi optimal ekanligini aniqlash qoladi, bu sizga sahifani iloji boricha moslashtirishga imkon beradi va sanktsiyalarga olib kelmaydi. Keling, birinchi navbatda, ko'pchilik (ehtimol, barcha) qidiruv tizimlari reyting uchun foydalanadigan formulani eslaylik.
Kalitdan foydalanishning ruxsat etilgan chastotasini qanday aniqlash mumkin
Biz yuqorida aytib o'tilgan maqolada matematik model haqida gapirgan edik. Ushbu aniq qidiruv so'rovi uchun uning mohiyati bitta soddalashtirilgan formula bilan ifodalanadi: TF*IDF. Bu erda TF - bu so'rovning hujjat matnida to'g'ridan-to'g'ri paydo bo'lish chastotasi (unda so'zlarning paydo bo'lish chastotasi).
IDF - ma'lum bir qidiruv tizimi (to'plamda) tomonidan indekslangan boshqa barcha Internet hujjatlarida berilgan so'rovning paydo bo'lishining teskari chastotasi (kamdan-kam hollarda).
Ushbu formula hujjatning qidiruv so'roviga muvofiqligini (muvofiqligini) aniqlash imkonini beradi. TF*IDF mahsulotining qiymati qanchalik baland bo'lsa, hujjat shunchalik dolzarb bo'ladi va u qanchalik baland bo'lsa, qolgan barcha narsalar teng bo'ladi.
Bular. ma'lum bo'lishicha, berilgan so'rov uchun hujjatning og'irligi (uning muvofiqligi) kattaroq bo'ladi, bu so'rovning kalitlari matnda qanchalik tez-tez ishlatiladi va bu kalitlar boshqa Internet hujjatlarida kamroq uchraydi.
Biz IDFga ta'sir qila olmasligimiz aniq, faqat biz optimallashtiradigan boshqa so'rovni tanlashdan tashqari. Ammo biz TF ga ta'sir qila olamiz va ta'sir qilamiz, chunki biz Yandex va Google qidiruv natijalaridan bizga kerakli foydalanuvchi savollari bo'yicha trafikning ulushini (va kichik emas) olishni xohlaymiz.
Ammo haqiqat shundaki, qidiruv algoritmlari TF qiymatini juda ayyor formuladan foydalangan holda hisoblaydi, bu matnda kalit so'zlardan foydalanish chastotasining faqat ma'lum bir chegaragacha ko'payishini hisobga oladi, shundan so'ng TF o'sishi amalda to'xtaydi, shunga qaramay. chastotani oshirganingiz haqiqat. Bu antispam filtrining bir turi.
Nisbatan uzoq vaqt oldin (taxminan 2005 yilgacha) TF qiymati juda oddiy formuladan foydalangan holda hisoblangan va aslida kalit so'zning paydo bo'lish zichligiga teng edi. Ushbu formuladan foydalangan holda tegishlilikni hisoblash natijalari qidiruv tizimlariga unchalik yoqmadi, chunki ular spamerlarga murojaat qilishdi.
Keyin TF formulasi murakkablashdi, sahifa ko'ngil aynishi kabi tushuncha paydo bo'ldi va u nafaqat paydo bo'lish chastotasiga, balki xuddi shu matnda boshqa so'zlarni qo'llash chastotasiga ham bog'liq bo'la boshladi. Agar kalit eng ko'p ishlatiladigan so'z bo'lib chiqsa, optimal TF qiymatiga erishish mumkin edi.
Shuningdek, yuzaga kelish foizini saqlab, matn hajmini oshirish orqali TF qiymatini oshirish mumkin edi. Bir xil foizli kalitlarga ega bo'lgan maqola bilan sochiq qanchalik katta bo'lsa, hujjat shunchalik yuqori bo'ladi.
Endi TF formulasi yanada murakkablashdi, lekin shu bilan birga, endi matn o'qilmaydigan bo'lib qolganda zichlikni qiymatga etkazishimiz shart emas. qidiruv tizimlari yuklaydi spam uchun loyihamizni taqiqlash. Va endi nomutanosib uzun varaqlarni yozishning hojati yo'q.
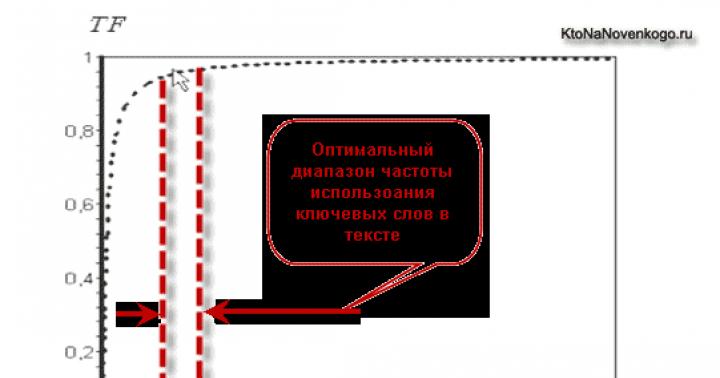
Bir xil ideal zichlikni saqlagan holda (biz uni mos keladigan grafikdan biroz pastroqda aniqlaymiz), maqola hajmini so'z bilan oshirish uning qidiruv natijalaridagi o'rnini faqat ma'lum bir uzunlikgacha yaxshilaydi. Ideal uzunlikka ega bo'lganingizdan so'ng, uni yanada oshirish dolzarblikka ta'sir qilmaydi (aniqrog'i, bu bo'ladi, lekin juda, juda oz).
Agar siz ushbu murakkab TF (to'g'ridan-to'g'ri sodir bo'lish chastotasi) asosida grafik tuzsangiz, bularning barchasini aniq ko'rish mumkin. Agar ushbu grafikning bir shkalasida TF, boshqa shkalada esa - matnda kalit so'zning paydo bo'lish chastotasi foizi bo'lsa, natijada biz giperbola deb ataladigan narsani olamiz:

Grafik, albatta, taxminiydir, chunki Yandex yoki Google foydalanadigan haqiqiy TF formulasini kam odam biladi. Lekin uni sifat jihatidan aniqlash mumkin optimal diapazon, unda chastota joylashgan bo'lishi kerak. Bu umumiy so'zlarning taxminan 2-3 foizini tashkil qiladi.
Agar siz ba'zi kalitlarni urg'u teglari va TITLE sarlavhasiga ham qo'shasiz deb hisoblasangiz, bu chegara bo'ladi, shundan so'ng zichlikning yanada oshishi taqiqlanishi mumkin. Ko'p sonli kalit so'zlar bilan matnni to'ldirish va buzish endi foydali emas, chunki ortiqchalardan ko'ra ko'proq minuslar bo'ladi.
Targ'ibot uchun qancha uzunlikdagi matn etarli bo'ladi?
Xuddi shu taxmin qilingan TF ga asoslanib, uning qiymatini so'z bilan uzunlik bilan taqqoslash mumkin. Bunday holda, kalit so'zlarning chastotasini istalgan uzunlik uchun doimiy va teng, masalan, optimal diapazondan istalgan qiymatga (2 dan 3 foizgacha) olishingiz mumkin.
Shunisi e'tiborga loyiqki, biz yuqorida muhokama qilingan shaklga o'xshash grafikni olamiz, faqat matnning minglab so'zlardan iborat uzunligi x o'qi bo'ylab o'rnatiladi. Va undan xulosa chiqarish mumkin bo'ladi optimal uzunlik oralig'i, bunda deyarli maksimal TF qiymati allaqachon erishilgan.
Natijada, u 1000 dan 2000 gacha so'zlar oralig'ida bo'ladi. Keyinchalik o'sish bilan dolzarblik deyarli o'smaydi va qisqaroq uzunlik bilan u keskin pasayadi.
Bu. Xulosa qilishimiz mumkinki, sizning maqolalaringiz qidiruv natijalarida yuqori o'rinlarni egallashi uchun siz matnda kamida 2-3% chastotali kalit so'zlardan foydalanishingiz kerak. Bu biz qilgan birinchi va asosiy xulosa. Xo'sh, ikkinchi narsa shundaki, endi yuqoriga chiqish uchun juda katta hajmli maqolalar yozish shart emas.
1000-2000 so'z chegarasidan oshib ketish va unga 2-3% kalit so'zlarni kiritish kifoya qiladi. Hammasi shu - tamom mukammal matn uchun retsept, tashqi optimallashtirishdan foydalanmasdan ham past chastotali so'rovlar bo'yicha yuqori o'rin uchun raqobatlasha oladi (ushbu maqolaga kalitlarni o'z ichiga olgan langarlar bilan havolalarni sotib olish). Vaholanki, atrofni biroz chalg'it Miralinkse , GGL, Rotapost yoki GetGoodLink, mumkin, chunki u sizning loyihangizga yordam beradi.
Yana bir bor eslatib o'tamanki, siz yozgan matnning uzunligini, shuningdek, undagi ba'zi kalit so'zlarni ishlatish chastotasini, ixtisoslashtirilgan dasturlardan yoki ularni tahlil qilishga ixtisoslashgan onlayn xizmatlardan foydalanishni bilib olishingiz mumkin. Ushbu xizmatlardan biri ISTIO, kim bilan gaplashganim haqida.
Men yuqorida aytgan hamma narsa yuz foiz ishonchli emas, lekin haqiqatga juda o'xshash. Har holda, mening shaxsiy tajribam bu nazariyani tasdiqlaydi. Ammo Yandex va Google-ning algoritmlari doimiy ravishda o'zgarishlarga duch keladi va ularning rivojlanishiga yoki ishlab chiquvchilarga yaqin bo'lganlar bundan mustasno, ertaga qanday bo'lishini kam odam biladi.
Omad sizga! Tez orada blog sayti sahifalarida ko'rishguncha
Sizni qiziqtirishi mumkin
 Ichki optimallashtirish - kalit so'zlarni tanlash, ko'ngil aynishini tekshirish, optimal sarlavha, tarkibni takrorlash va LF ostida bog'lash
Ichki optimallashtirish - kalit so'zlarni tanlash, ko'ngil aynishini tekshirish, optimal sarlavha, tarkibni takrorlash va LF ostida bog'lash  Matn va sarlavhalardagi kalit so'zlar
Matn va sarlavhalardagi kalit so'zlar  Kalit so'zlar qidiruv tizimlarida veb-sayt reklamasiga qanday ta'sir qiladi
Kalit so'zlar qidiruv tizimlarida veb-sayt reklamasiga qanday ta'sir qiladi  Veb-ustalar uchun onlayn xizmatlar - maqolalar yozish, qidiruv tizimini optimallashtirish va uning muvaffaqiyatini tahlil qilish uchun kerak bo'lgan hamma narsa
Veb-ustalar uchun onlayn xizmatlar - maqolalar yozish, qidiruv tizimini optimallashtirish va uning muvaffaqiyatini tahlil qilish uchun kerak bo'lgan hamma narsa  Xarajatlarni minimallashtirish uchun havolani targ'ib qilishda tarkibni optimallashtirish va sayt mavzusini hisobga olish usullari
Xarajatlarni minimallashtirish uchun havolani targ'ib qilishda tarkibni optimallashtirish va sayt mavzusini hisobga olish usullari  Yandex Wordstat va semantik yadro - Wordstat.Yandex.ru onlayn xizmatidan statistik ma'lumotlardan foydalangan holda veb-sayt uchun kalit so'zlarni tanlash
Yandex Wordstat va semantik yadro - Wordstat.Yandex.ru onlayn xizmatidan statistik ma'lumotlardan foydalangan holda veb-sayt uchun kalit so'zlarni tanlash  Anchor - bu nima va ular veb-saytni reklama qilishda qanchalik muhim?
Anchor - bu nima va ular veb-saytni reklama qilishda qanchalik muhim?  Qanday qidiruv tizimini optimallashtirish omillari veb-sayt reklamasiga ta'sir qiladi va qay darajada?
Qanday qidiruv tizimini optimallashtirish omillari veb-sayt reklamasiga ta'sir qiladi va qay darajada?  Saytni o'zingiz targ'ib qilish, reklama qilish va optimallashtirish
Saytni o'zingiz targ'ib qilish, reklama qilish va optimallashtirish  Tilning morfologiyasini va qidiruv tizimlari tomonidan hal qilinadigan boshqa muammolarni, shuningdek yuqori chastotali, o'rta diapazonli va past chastotali so'rovlar o'rtasidagi farqni hisobga olgan holda
Tilning morfologiyasini va qidiruv tizimlari tomonidan hal qilinadigan boshqa muammolarni, shuningdek yuqori chastotali, o'rta diapazonli va past chastotali so'rovlar o'rtasidagi farqni hisobga olgan holda  Sayt ishonchi - bu nima, uni XTools-da qanday o'lchash kerak, unga nima ta'sir qiladi va saytingizning obro'sini qanday oshirish mumkin
Sayt ishonchi - bu nima, uni XTools-da qanday o'lchash kerak, unga nima ta'sir qiladi va saytingizning obro'sini qanday oshirish mumkin
Foydalanish chastotasi
ism, sinonimlar soni: 1
foydalanish (10)
- - ma'lum sabablarga ko'ra foydalanish cheklangan lug'at. ekstralingvistik sabablar. L.o.u.ga. o'z ichiga oladi: dialektizmlar, atamalar va professionalizmlar, jargon, so'zlashuv so'zlari va iboralar, vulgarizmlar...
Sotsialingvistik atamalar lug'ati
-
Umumiy tilshunoslik. Ijtimoiy lingvistika: Lug'at-ma'lumotnoma
- - grammatik shakllarning o'rnatilgan qo'llanilishini belgilash uchun Delbryuk tomonidan kiritilgan Gebrauchstypen nemis atamasi tarjimasi. T. yuqoriga. masalan, sintaktik foydalanishning har xil turlarini o'z ichiga oladi ...
Brockhaus va Euphron entsiklopedik lug'ati
- - qo'llanilishi ekstralingvistik sabablarga ko'ra cheklangan lug'at: 1) hududiy jihatdan cheklangan dialektizmlar; 2) ilmiy uslubda ishlatiladigan atamalar...
-
Lingvistik atamalar lug'ati T.V. Kuy
-
Lingvistik atamalar lug'ati T.V. Kuy
- - Bir ob'ekt va boshqa ob'ekt o'rtasidagi farqlardan foydalanishni taqiqlovchi foydalanish: Tirik organizmlar ...siz mavjud bo'lolmaydi.
- - Berilgan ob'ektlar sinfining o'ziga xos vakillari bilan bog'liq bo'lgan foydalanish: Men bu odamni ko'rishim kerak ...
Umumiy morfologiyaning atama va tushunchalari: Lug'at-ma'lumotnoma
- - 1) Murakkab birlashmagan jumlalarni formatlash qoidalarida ko'zda tutilgan variantlar: tushuntirish yoki turtki berishda ikki nuqta o'rniga chiziqcha qo'llanilishi mumkin: Ajratish xayoliy - biz tez orada birga bo'lamiz ...
Sintaksis: Lug'at
- - ergash gap, sinonimlar soni: 1 ta yashirin...
Sinonim lug'at
- - ad., sinonimlar soni: 10 ta nashr etilgan, eskirgan, zamonaviy talablarga javob bermaydigan, eskirgan, eskirgan, afsonaviy doiraga tushib qolgan...
Sinonim lug'at
- - Sm....
Sinonim lug'at
- - adj., sinonimlar soni: 19 anaxronistik arxaik arxaik bosma eskirgan eskirgan eskirgan eskirgan eskirgan eskirgan eskirgan nafaqaga chiqqan mintaqaga...
Sinonim lug'at
- - adj., sinonimlar soni: 2 ta foydalanishga yaroqsiz kamdan-kam...
Sinonim lug'at
- - si., sinonimlar soni: 3 ta foydalanilmagan, chetga qoʻy, qopqoq ostida...
Sinonim lug'at
- - 1) Murakkab birlashmagan jumlalarni formatlash qoidalarida ko'zda tutilgan variantlar: tushuntirish yoki turtki berishda ikki nuqta o'rniga tire qo'llanilishi mumkin: Ajratish xayoliy - biz yaqinda birga bo'lamiz 2) Izolyatsiya bilan ...
Lingvistik atamalar lug'ati T.V. Kuy
kitoblarda "foydalanish chastotasi"
Oziqlantirish chastotasi
Harmar Xilleri tomonidanOziqlantirish chastotasi
Harmar Xilleri tomonidanOziqlantirish chastotasi Kuchukcha uchun kuniga zarur bo'lgan ovqatlanish soni zotning kattaligiga bog'liq. Ko'pgina kuchukchalar kechayu kunduz har uch soatda ovqatlansa, yaxshi rivojlanadi, ammo agar ular muddatidan oldin tug'ilgan bo'lsa yoki tug'ilganda vazni 85 g dan kam bo'lsa, ehtimol ular
Oziqlantirish chastotasi
Itlarni etishtirish kitobidan Harmar Xilleri tomonidanOziqlantirish chastotasi Kuchukcha uchun kuniga zarur bo'lgan ovqatlanish soni zotning kattaligiga bog'liq. Ko'pgina kuchukchalar kechayu kunduz har uch soatda ovqatlansa, yaxshi rivojlanadi, ammo agar ular muddatidan oldin tug'ilgan bo'lsa yoki tug'ilganda vazni 85 g dan kam bo'lsa, ehtimol ular
Oziqlantirish chastotasi
Itlar va ularning nasl-nasabi kitobidan [It etishtirish] Harmar Xilleri tomonidanOziqlantirish chastotasi Kuchukcha uchun kuniga zarur bo'lgan ovqatlanish soni zotning kattaligiga bog'liq. Ko'pgina kuchukchalar kechayu kunduz har uch soatda ovqatlansa, yaxshi rivojlanadi, ammo agar ular muddatidan oldin tug'ilgan bo'lsa yoki tug'ilganda vazni 85 g dan kam bo'lsa, ehtimol ular
Chastotasi
Ko'chmas mulk kitobidan. Uni qanday reklama qilish kerak muallif Nazoikin Aleksandr14.2.3. O'zaro ta'sir chastotasi
Dimitri Nikolay tomonidan14.2.3. O'zaro munosabatlarning chastotasi Bir xil raqobatchilar guruhi qanchalik tez-tez o'zaro aloqada bo'lsa, kelishuv shunchalik barqaror bo'ladi, chunki qoidabuzarliklar tezroq jazolanadi. Agar, masalan, firmalar kamroq raqobatlashsa, ularning til biriktirish qobiliyati past bo'ladi.
15.4.6. Auktsion chastotasi
Xarid qilish bo'yicha qo'llanma kitobidan Dimitri Nikolay tomonidan15.4.6. Kim oshdi savdolarining chastotasi Yuqorida aytib o'tilganidek, ba'zi auktsion halqalari o'zlari til biriktirgan kim oshdi savdosidan so'ng o'zaro pul mablag'larini o'tkazishlari mumkin yoki faqat vaqti-vaqti bilan to'lanishi kerak bo'lgan summalarni hisobga olishlari mumkin.
8. Funksional so‘zlarning qo‘llanish chastotasi muallifning o‘zgarmasligi bo‘lib chiqadi
Kitobdan kitob 2. Biz sanalarni o'zgartiramiz - hamma narsa o'zgaradi. [Yunoniston va Injilning yangi xronologiyasi. Matematika o'rta asr xronologlarining aldovini ochib beradi] muallif Fomenko Anatoliy Timofeevich8. Funksional so‘zlarning qo‘llanish chastotasi muallifning o‘zgarmasligi bo‘lib chiqadi.E’tiborga molik istisno bu bizning 3-parametrimiz – barcha funksiyali so‘zlarning qo‘llanish chastotasi – PROPSITIONS, CONJUNCTIONS VA PARTICLES. Namuna hajmining o'sishiga qarab ushbu parametrning evolyutsiyasi ko'rsatilgan
Chastotasi
Muallifning Buyuk Sovet Entsiklopediyasi (CA) kitobidan TSBChastotasi
muallif Nazoikin AleksandrChastotasi
100 uchun media rejalashtirish kitobidan muallif Nazoikin AleksandrChastotali televizion kanallar metr va dekimetr chastotalarida efirga uzatiladi. Televizorda birinchi bo'lib metr diapazonlari o'zlashtirildi. 20-asrning 90-yillarida Moskvada dekimetrli kanallar faol ishlay boshladi.Ilgari chastota muhim ahamiyatga ega edi, chunki turli kanallarni qabul qilish uchun
Chastotasi
100 uchun media rejalashtirish kitobidan muallif Nazoikin AleksandrChastota Signalni uzatish chastotasi uning sifatini belgilaydi. Ko'proq darajada u VHF diapazonlarida (chastota modulyatsiyasi FM) taqdim etiladi. Tinglovchilar yaxshi ovozni afzal ko'radilar, shuning uchun VHF stantsiyalari sezilarli auditoriya reytingiga ega va afzalroqdir
3.2. Chastotasi
muallif Ivanov Dmitriy Olegovich3.2. Tez-tezligi Har qanday patologiyaning tibbiyotdagi ahamiyati haqida gapirganda, bizning fikrimizcha, nafaqat sodir bo'lgan yoki yuzaga kelishi mumkin bo'lgan shikastlanishlar va asoratlarning etiologiyasi, patogenezi, klinik ko'rinishi va og'irligi haqida gapirish kerak. Ushbu patologiyaning tarqalishi. TO
4.2. Chastotasi
Yangi tug'ilgan chaqaloqlarda issiqlik balansining buzilishi kitobidan muallif Ivanov Dmitriy Olegovich4.2. Chastotasi Yangi tug'ilgan chaqaloqlarda gipertermiya, ehtimol, hipotermiyaga qaraganda ancha kam uchraydi. Bu, ehtimol, ilmiy adabiyotlarda chaqaloqlarda gipertermiya bo'yicha juda kam tadqiqotlar mavjudligi bilan bog'liq. Maayan-Metzger A. va boshqalar. (2003) 42 313 ta ish hisobotini tahlil qildi
Chastotasi
Yangi tug'ilgan chaqaloqlarda glyukoza metabolizmining buzilishi kitobidan muallif Ivanov Dmitriy OlegovichFrequency Corblant M., gipoglikemiyani hayotning dastlabki 72 soatida 30 mg% dan kam (1,67 mmol/l) qondagi glyukoza konsentratsiyasi deb ta'riflagan, uni barcha tirik tug'ilganlarning 4,4% da aniqlagan.1971 yilda Lubchenco L. O. va Bard. N., Corblant M. mezonlaridan foydalangan holda, yangi tug'ilgan chaqaloqlarda gipoglikemiyani aniqladi.
Muammoning qisqacha bayoni
Turli janrdagi badiiy adabiyotlardan tortib yangiliklar reportajlarigacha rus tilidagi matnlar to'plami mavjud. Nutqning boshqa qismlari bilan predloglardan foydalanish bo'yicha statistik ma'lumotlarni to'plash kerak.
Vazifadagi muhim fikrlar
1. Old gaplar orasida nafaqat bor da Va Kimga, lekin predlog sifatida ishlatiladigan so'zlarning barqaror birikmalari, masalan ga qaraganda yoki ga qaramasdan. Shuning uchun siz matnlarni bo'shliqlar bo'yicha kesib bo'lmaydi.
2. Matnlar juda ko'p, bir necha GB, shuning uchun ishlov berish juda tez, kamida bir necha soat ichida bo'lishi kerak.
Yechim sxemasi va natijalari
Matnni qayta ishlash bilan bog'liq muammolarni hal qilishda mavjud tajribani hisobga olgan holda, o'zgartirilgan "unix-way" ga rioya qilishga qaror qilindi, ya'ni qayta ishlashni bir necha bosqichlarga bo'lish, shunda har bir bosqichda natija oddiy matn bo'ladi. Sof unix usulidan farqli o'laroq, matnli xom ashyoni kanallar orqali uzatish o'rniga, biz hamma narsani disk fayllari sifatida saqlaymiz. Yaxshiyamki, qattiq diskdagi gigabaytning narxi hozir juda kam.
Har bir bosqich alohida, kichik va oddiy yordamchi dastur sifatida amalga oshiriladi, u matnli fayllarni o'qiydi va kremniyning ishlash muddatini saqlaydi.
Ushbu yondashuvning qo'shimcha bonusi, yordamchi dasturlarning soddaligiga qo'shimcha ravishda, yechimning bosqichma-bosqich xususiyatidir - siz birinchi bosqichni disk raskadrovka qilishingiz, u orqali barcha gigabayt matnlarni ishga tushirishingiz, keyin vaqtni behuda sarf qilmasdan ikkinchi bosqichni tuzatishni boshlashingiz mumkin. birinchisini takrorlash.
Matnni so'zlarga ajratish
Qayta ishlanishi kerak bo'lgan manba matnlari allaqachon utf-8 kodlashda tekis fayllar sifatida saqlanganligi sababli, biz nol bosqichni o'tkazib yuboramiz - hujjatlarni tahlil qilish, ulardan matn tarkibini ajratib olish va ularni oddiy matn fayllari sifatida saqlash, to'g'ridan-to'g'ri tokenizatsiya vazifasiga o'tamiz.
Agar rus tilidagi ba'zi predloglar bo'sh joy va ba'zan vergul bilan ajratilgan bir nechta "chiziqlar" dan iborat bo'lmaganda, hamma narsa oddiy va zerikarli bo'lar edi. Bunday batafsil predloglarni parchalab tashlamaslik uchun birinchi navbatda API lug'atidagi tokenizatsiya funktsiyasini qo'shdim. C# dagi tartib oddiy va murakkab bo'lmagan, tom ma'noda yuz qator bo'lib chiqdi. Mana manba. Agar biz kirish qismini bekor qilsak, lug'atni yuklasak va uning o'chirilishi bilan yakuniy qismni o'chirib tashlasak, barchasi bir necha o'nlab qatorlarga tushadi.
Bularning barchasi fayllarni muvaffaqiyatli maydalaydi, ammo sinovlar muhim kamchilikni aniqladi - juda past tezlik. X64 platformasida u daqiqada taxminan 0,5 MB bo'lib chiqdi. Albatta, tokenizer har qanday maxsus holatlarni hisobga oladi " A.S. Pushkin", lekin asl muammoni hal qilish uchun bunday aniqlik kerak emas.
Mumkin bo'lgan tezlik bo'yicha qo'llanma sifatida Empirika deb nomlangan statistik fayllarni qayta ishlash dasturi mavjud. U taxminan 2 soat ichida 22 Gb matnlarni chastotali qayta ishlashni amalga oshiradi. Ko'p so'zli predloglar muammosiga tezroq yechim bor, shuning uchun men buyruq satrida -tokenize opsiyasi tomonidan yoqilgan yangi skriptni qo'shdim. Ishlash natijalari 900 MB uchun taxminan 500 soniya, ya'ni soniyasiga taxminan 1,6 MB bo'lib chiqdi.
Ushbu 900 MB matn bilan ishlash natijasi taxminan bir xil o'lchamdagi fayl, 900 MB. Har bir so'z alohida satrda saqlanadi.
Old gaplarning qo'llanish chastotasi
Men dastur matniga predloglar ro'yxatini kiritishni istamaganim uchun C# loyihasiga yana grammatika lug'atini biriktirdim, sol_ListEntries funksiyasidan foydalanib, men predloglarning to'liq ro'yxatini oldim, taxminan 140 dona, keyin hammasi ahamiyatsiz. Dasturning C# tilidagi matni. U faqat predlog + so'z juftlarini to'playdi, lekin uni kengaytirish muammo bo'lmaydi.
1 GB hajmli matnli faylni so'zlar bilan qayta ishlash bir necha daqiqa davom etadi, natijada chastotalar jadvali paydo bo'ladi, biz uni yana matn fayli sifatida diskga yuklaymiz. Unda predlog, ikkinchi so'z va foydalanish soni yorliq belgisi bilan ajratilgan:
BUZILGANLAR HAQIDA 3
1 GOL OLGAN HAQIDA
1-FORM HAQIDA
NORM HAQIDA 1
OCH HAQIDA 1
HUQUQIY 9
TERRASADAN 1
1-lentaga qaramay
ustki tortmacha 14
Hammasi bo'lib, asl 900 MB matndan taxminan 600 ming juft olingan.
Natijalarni tahlil qilish va ko'rish
Excel yoki Access-da natijalar bilan jadvalni tahlil qilish qulay. SQL odatim tufayli men ma'lumotlarni Accessga yukladim.
Siz qilishingiz mumkin bo'lgan birinchi narsa, eng keng tarqalgan juftlarni ko'rish uchun natijalarni chastotaning kamayishi tartibida tartiblashdir. Qayta ishlangan matnning dastlabki hajmi juda kichik, shuning uchun namuna unchalik ishonchli emas va yakuniy natijalardan farq qilishi mumkin, ammo bu erda eng yaxshi o'ntalik:
BIZDA 29193
V TOM 26070
Menda 25843 bor
TOM 24410 HAQIDA
U 22768 ga ega
BU 22502
20749 MUDDATDA
20545 YILDA
BU HAQIDA 18761
U BILAN 18411
Endi siz chastotalar OY o'qi bo'ylab, naqshlar esa kamayish tartibida OX bo'ylab chiziqli bo'lishi uchun grafik qurishingiz mumkin. Bu uzun quyruq bilan kutilgan taqsimotni beradi:
Nima uchun bu statistika kerak?
Protsessual API bilan ishlashni namoyish qilish uchun ikkita C# yordam dasturidan foydalanish mumkinligidan tashqari, yana bir muhim maqsad bor - tarjimon va matnni qayta qurish algoritmi uchun statistik xom ashyo bilan ta'minlash. Juft so'zlarga qo'shimcha ravishda sizga trigrammalar ham kerak bo'ladi, buning uchun sizga yuqorida ko'rsatilgan yordamchi dasturlarning ikkinchisini biroz kengaytirish kerak bo'ladi.